요약
임상 데이터의 체계적 수집 및 관리를 위해 데이터를 재구성하였습니다. 1개의 표에 모든 정보를 기록하고 있던 기존 데이터 수집 체계를 5개의 excel 파일, 18개의 table로 분리하였고, 기존 자료 (2024년 6월 28일 기준) 내용을 입력하였습니다. 비슷한 의미를 지닌 단위를 데이터를 분류하여, 각각의 데이터를 쉽게 관리하는 것이 목적입니다.
데이터 관리 측면에서는 출력 (fetch), 입력 (insert), 수정 (update), 삭제(delete)로 분리하였습니다. 각 과정은 excel 파일 작성, web server 업로드, 작업 처리로 나누어 진행합니다. 예를 들어 특정 table의 내용을 수정하기 위해서는 데이터베이스에서 fetch 명령을 이용해 전체 테이블을 excel 파일로 출력하고, 그 파일을 수정한 후 서버에 업로드 하고 update 명령을 실행해 database에 수정 사항을 반영할 수 있습니다.
Database 사용 방법
데이터베이스에서 데이터를 가져오고 (fetch), 데이터베이스에 새로운 데이터를 입력 (insert)하거나, 기존 데이터를 수정 (update)하거나 삭제 (delete)할 수 있습니다. 이를 위해서 각각 fetch, insert, update, delete 기능을 제공합니다. 이 때 데이터는 모두 excel 파일을 이용해 관리합니다. 즉, excel파일을 작성하고, 이를 server에 업로드하고 명령을 실행하여 database를 이용합니다.
이미 많은 데이터를 입력했기 때문에, 해당 데이터를 최대한 살려서 데이터베이스를 구성하였기 때문에 데이터 update를 먼저 설명합니다.
1. Update – 데이터 수정
이미 입력한 데이터를 수정하기 위해서는 입력 데이터를 먼저 가져온 후 (fetch), 그 내용을 수정하고, 데이터베이스를 수정 (update)합니다.
1-1. 서버 접속
데이터베이스를 활용하기 위해서 서버에 접속합니다. Web browser에 아래 URL을 입력하고 사용자 ID와 비밀번호를 입력합니다.
http://bdsl.jbnu.ac.kr:13000
1-2. 데이터 가져오기
데이터베이스의 내용을 가져오기 위해서는 1_fetch.ipynb notebook을 이용합니다. Notebook 파일을 클릭하면, 아래와 같은 화면이 보이고 여기에서 ⏩ 버튼을 누릅니다. 명령 진행 후 1_table 디렉토리에 5개의 excel 파일이 생성됩니다. 각 파일을 우클릭하고 ‘download’ 명령을 선택합니다. 보안 정책 관련 경고는 무시하고 파일을 받습니다.
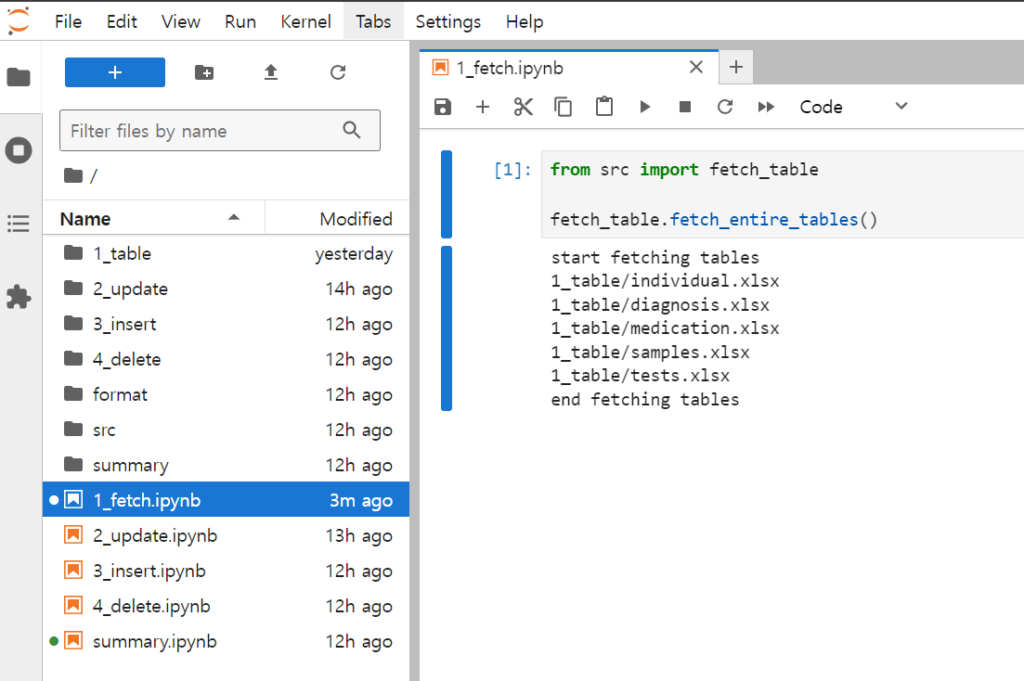
1-3. 데이터 수정하기
Excel 파일의 데이터를 수정합니다.
(주의 사항 1) id 는 데이터베이스에서 각 데이터를 식별하기 위한 값으로 절대 임의로 변경해서는 안 됩니다.
(주의 사항 2) 편의상 해당 테이블의 데이터 이외의 chart_index와 hospital_id, name을 같이 출력하였습니다. 해당 항목은 “supp_” suffix를 이용해 표기되어 있고, 해당 항목의 값을 변경하여도 데이터베이스에서 변경되지 않습니다. 이 값들을 변경하기 위해서는 원 데이터를 변경해야 합니다. 예를 들어 이름을 변경하기 위해서는 individual.xlsl 파일의 private sheet의 name 항목의 값을 변경하고 update 해야 합니다.
(주의 사항 3) excel에 새로운 항목을 추가하여도 데이터베이스에 반영되지는 않습니다. 데이터 전체 구조를 변경해야 하는 사항이므로, 먼저 관리자에게 연락해서 변경한 후, 다시 출력하고 입력합니다.
1-4. 수정 내역 반영하기
수정 한 excel 파일을 서버의 2_update 디렉토리에 복사 합니다. 해당 디렉토리를 열고 file navigation panel (왼쪽 패널)로 파일을 drag & drop 해서 복사할 수 있습니다. 다음으로, 2_update.ipynb 파일을 열고 ⏩ 버튼을 누릅니다.
수정 반영 사항이 있으면 출력됩니다. 각각의 파일은 diagnosis, individual, medication, samples, tests로 시작해야 합니다. 해당 suffix 뒤에 추가적인 정보를 입력할 수 도 있습니다. 예를 들어 diagnosis_240710.xlsx 과 같은 파일 이름을 사용할 수 있습니다.
(주의 사항) 2_update 폴더의 모든 파일에 대한 update가 진행됩니다. 이미 업데이트를 진행했다면, 해당 파일을 삭제해야 합니다.
(주의 사항) 수정시 업로드 하는 file에 있는 값이 데이터베이스의 값과 같은 경우 무시됩니다.
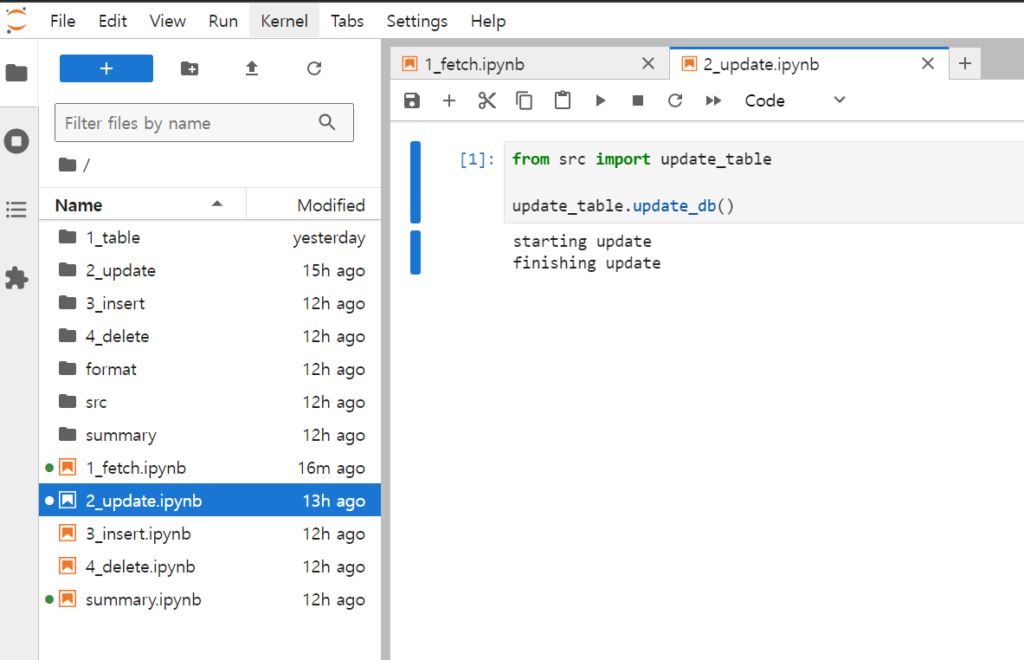
2. Fetch – 데이터 받기
Update를 설명하면서 데이터베이스 값을 받는 방법은 설명하였으나, 간략히 다시 설명합니다. 서버에 접속하여 1_fetch.ipynb notebook 파일을 열고, ⏩ 버튼을 누르면, 서버는 데이터베이스에서 전체 데이터를 받고 이를 excel 파일로 변환합니다. 변환된 파일은 1_table 디렉토리에서 확인합니다.
1_table은 전체 데이터를 보여주고, 데이터 입력을 돕기 위해 환자번호와 환자명과 같은 추가 정보를 표기하였습니다. 해당 정보 이외의 정보가 필요할 수도 있을 것 같습니다. 어떤 정보가 필요한지 알려주시면 해당 정보도 같이 표기할 수 있으니 알려주시기 바랍니다.
3. Insert – 신규 데이터 입력
신규 데이터는 아래의 template excel을 작성하여 진행합니다. 신규 데이터 입력시 각 table에 iid 항목이 꼭 필요합니다. 이 항목을 이용해서 모든 데이터가 연결되기 때문입니다. 그리고, 이미 입력한 값이 다시 입력되지 않도록 주의해야 합니다.
3-1. 신규 데이터 파일 작성
아래 template 파일을 이용하여 신규 데이터를 입력합니다. 새로운 항목을 작성할 때는 아래 파일을 download 하고 새로 작성하는 것을 추천합니다.
3-2. 파일 업로드
작성한 파일을 웹서버의 3_insert 디렉토리에 복사합니다. 가능하면 insertion이 끝난 파일은 삭제합니다.
3-3. 데이터 입력
3_insert.ipynb 파일을 열고 ⏩ 버튼을 눌려 실행하면, 3_insert의 파일을 일고, 데이터베이스를 업데이트 합니다. 새로 입력되는 데이터에 대한 정보가 화면에 출력됩니다. 오류가 있는 값을 확인하고, 해당 입력에 대해서는 새로운 insert 파일을 만들고 값을 다시 입력합니다.
4. delete – 데이터 삭제
한번 삭제한 데이터는 복원이 어려우니 삭제는 매우 신중하게 진행해야 합니다.
4-1. 데이터 받기
데이터를 삭제하기 위해서는 삭제할 항목에 대한 id 를 알아야 합니다. 이를 위해서 1_fetch.ipynb 노트북을 이용해 데이터베이스로 부터 가장 최근 데이터를 받습니다. 그리고, 해당 table에서 삭제할 데이터의 id 값을 기록하고, 이를 삭제를 위한 excel 파일에 기록합니다. 이 파일은 다음 sub-section에서 설명합니다.
4-2. 삭제 파일 만들기
데이터 삭제를 위한 파일도 update, insert와 같은 비슷한 파일명을 지니고 있습니다. 하지만, 각 table은 id 항목만 가지고 있습니다. 각 table에서 해당 id를 가진 항목을 제거하게 됩니다.
4-3. 삭제하기
삭제할 데이터의 id를 excel 파일들에 기록하였다면, 이 파일을 서버의 4_delete 디렉토리에 복사합니다. 이어서 4_delete.ipynb 명령을 실행하여, 해당 데이터를 서버에서 삭제할 수 있습니다.
방법
1. Google datasheet
임상데이터 원 자료
- https://docs.google.com/spreadsheets/d/1pwMJGcHiWGTcm519vDYbn7-elVlp6EBC4KmlukohVSQ/edit#gid=0
2. Data inspection and classification
전체 데이터의 항목을 분석하여 format을 변경하였습니다. 원래의 1개의 파일을 Individual, Diagnosis, Medication, Samples, Tests의 다섯 가지 항목 (category)를 정의하고, 5개의 excel 파일로 분리하였습니다. 각각의 파일에는 해당 정보들이 table 형태로 분리하였습니다.
3. Database models
분석한 데이터에 의해 전체 데이터 model을 구성하였습니다. 원 데이터의 table을 분리해서 개별 table을 구성했다고 생각하시면 됩니다. 테이블 속성 (colume 이름)은 영문으로 지정해야 하기 때문에 속성 값을 영문으로 교체하였습니다.
총 18개의 table을 구성하였고, 모든 table은 iid라는 속성을 지니고 있으며, 이는 개별 사람을 지칭하는 값입니다.
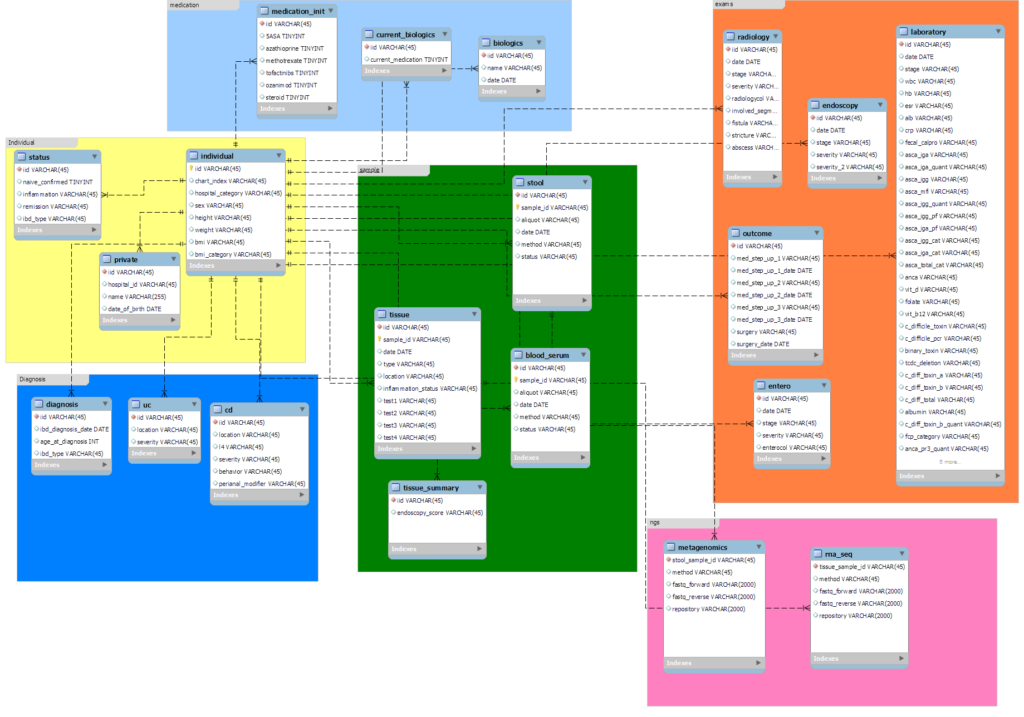
3-1. MySQL data model 구성
전체 데이터를 바탕으로 data table을 만들었습니다. 참고로 individual table은 개인에 대한 index인 iid를 가지고 있고, chart_index와, hospital_category (병원 index), 성별, 키 등의 정보를 가지고 있습니다. 이는 아래와 같은 항목을 포함합니다.
- 데이터 모델 파일 ![[snu_data_curation.mwb]]
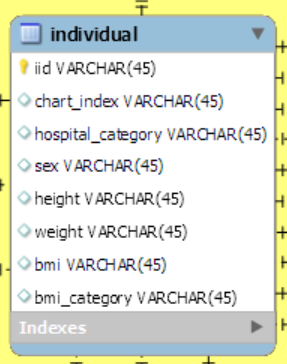
3-2. (예시) Individual
개인에 대한 정보는 아래와 같은 테이블로 정리하였습니다.
3-3. (예시) 개인 정보
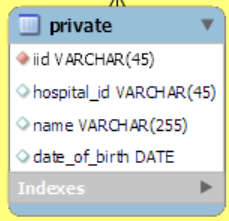
개인 정보와 관련된 데이터는 private 테이블에 있으며 아래와 같은 정보를 가지고 있습니다. 병원 index와 이름, 생년월일 정보를 포함하였습니다. 개인정보 보관 기한 초과 시 해당 정보를 일괄 삭제합니다.
4. Database server
MySQL database의 구성은 아래와 같습니다. Web server와 분리되는 서버로, 웹서버에서 해당 서버로 접속해서 데이터를 가져옵니다.
- 서버: BDSL-ds, MySQL
- Database: snu
5. Web server
데이터 관리 서버는 아래 URL을 이용해 접속 가능합니다.
http://bdsl.jbnu.ac.kr:13000
6. 데이터 항목 분석 – 5 categories – reformated input data file
원 데이터의 내용을 바탕으로, 데이터를 5개 항목, 18개 table로 분리하였습니다. 5개의 항목은 Individual, Diagnosis, Medication, Samples, Tests 이며 각각 개인에 대한 정보, 진단 정보, 투약 정보, 샘플 정보, 측정 정보를 포함하고 있습니다.
- Individual
- individual – 기본 정보
- private – 개인 정보
- status – 상태 정보
- Diagnosis
- diagnosis – 진단 정보
- UC – UC 관련 진단 정보
- CD – CD 관련 진단 정보
- Medication
- medication_init – 최초 등록 시 치료 정보
- current_biologics – 생물학제제 사용 상태
- biologics – 생물학제제 사용 기록
- Samples
- stool – 분변 샘플
- blood_serum – 혈액 샘플
- tissue – 조직 샘플
- tissue_summary – 조직 샘플 전체에 대한 정보
- Tests
- endoscopy – 내시경 실험 결과
- entero – 내시경 실험 결과
- radiology – 방사선 실험 결과
- laboratory – 혈액 실험 결과
- outcome – 치료 결과?