Introduction
Pattern은 반복되는 무늬나 서열을 의미한다. DNA 서열과 단백질 서열에는 다양한 종류의 pattern이 존재한다. 생체에서 이러한 패턴이 나타나는 이유는 기능과 밀접히 연관되어 있다. 동일한 transcription factor (TF) 에 의해 발현이 조절되는 유전자의 promoter에는 해당 TF가 인지하고 결합할 수 있는 특정 DNA 서열이 있다. 유사한 기능을 하는 단백질의 경우 해당 기능 수행을 위한 부위가 잘 보존되어 있다.
Pattern recognition
패턴을 찾기 위해서 통계, 기계학습, 인공지능 등의 다양한 방법이 동원된다. 수업에서는 Expectation Maximization (EM) 방법을 이용한 pattern 발굴 방법을 학습하였다. 그리고, multiple sequence alignment를 통해 서열 정열 후 잘 보존된 영역을 찾는 방법도 있으며, hidden markov model (HMM)을 이용해 서열 정보를 표현하는 방법 등 다양한 pattern 발굴 방법이 존재한다. 조금 더 일반적으로 이러한 pattern을 찾는 방법을 pattern recognition이라 한다 (https://en.wikipedia.org/wiki/Pattern_recognition).
InterPro
InterPro는 단백질 family, domain 등을 수집하여 그 pattern을 보관하고 있는 database이고, 이 pattern 정보를 이용하여 단백질 서열에 존재하는 family, domain 등의 특징을 표현한다.
예제 – pyruvate kinase
>sp|P11974|KPYM_RABIT Pyruvate kinase PKM OS=Oryctolagus cuniculus OX=9986 GN=PKM PE=1 SV=4
MSKSHSEAGSAFIQTQQLHAAMADTFLEHMCRLDIDSAPITARNTGIICTIGPASRSVET
LKEMIKSGMNVARMNFSHGTHEYHAETIKNVRTATESFASDPILYRPVAVALDTKGPEIR
TGLIKGSGTAEVELKKGATLKITLDNAYMEKCDENILWLDYKNICKVVDVGSKVYVDDGL
ISLQVKQKGPDFLVTEVENGGFLGSKKGVNLPGAAVDLPAVSEKDIQDLKFGVEQDVDMV
FASFIRKAADVHEVRKILGEKGKNIKIISKIENHEGVRRFDEILEASDGIMVARGDLGIE
IPAEKVFLAQKMIIGRCNRAGKPVICATQMLESMIKKPRPTRAEGSDVANAVLDGADCIM
LSGETAKGDYPLEAVRMQHLIAREAEAAMFHRKLFEELARSSSHSTDLMEAMAMGSVEAS
YKCLAAALIVLTESGRSAHQVARYRPRAPIIAVTRNHQTARQAHLYRGIFPVVCKDPVQE
AWAEDVDLRVNLAMNVGKARGFFKKGDVVIVLTGWRPGSGFTNTMRVVPVPInterPro 실행
https://ebi.ac.uk/interpro/에 FASTA format의 서열을 입력하고, family 혹은 domain 구조를 탐색한다.
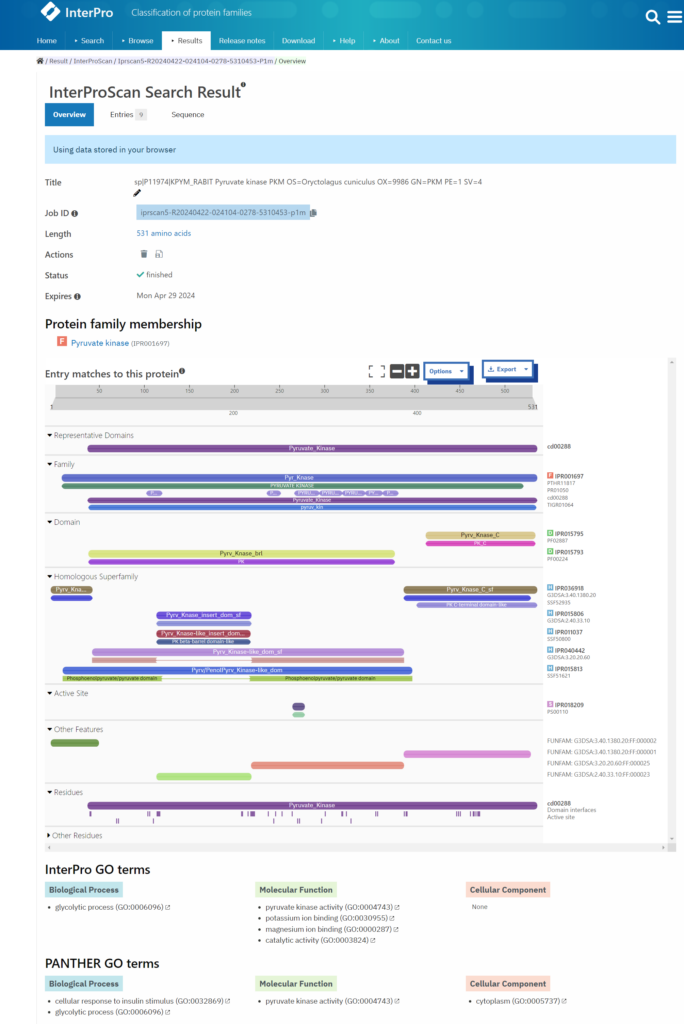
InterPro 결과
아래는 실행 결과의 예제로, pyruvate kinase가 두 개의 domain으로 구성되어 있음을 알 수 있다. 이외에도 family, homologous superfamily 등의 구조도 같이 찾을 수 있음을 확인할 수 있다.