소개
생물정보학 중간 과제는 학습한 생물정보학 방법을 활용하여 유전자의 기능을 탐색하는 연구 과제입니다.
연구 시작 전 terminal 창에서 다음 명령을 실행해 필요한 파일을 복사합니다.
cd ~
cp ../shared_data/MidTermProject . -r MidTermProject 폴더에는 I.ResearchNote.ipynb와 II.Report.ipynb 2개의 JupyterNotebook 파일이 있습니다. I.ResearchNote.ipynb에는 연구 과정에서 수집한 정보를 기록하고, II.Report.ipynb 에는 연구 수행 완료 결과를 정리하여 기록합니다.
I. 과제 진행
연구 과제를 진행하면서 수집한 정보들을 I.ResearchNote.ipynb에 기록합니다. Markdown cell을 이용해 정보를 기록합니다.
이 과제에서는 생명현상 관련 있는 유전자를 찾고, 해당 유전자의 기능을 연구합니다. 이를 위해서 평소 관심을 가지고 있던 생명현상을 조사하고, 그 현상에 관여하는 유전자를 찾고 그 유전자의 기능을 연구합니다. 이를 위해 첫 단계로 평소 관심을 가지고 있었던 다양한 주제에 대해 조사해 보고 이 내용을 1. 주제 선정에 기록합니다.
하나의 주제를 선정하고 그 주제에 대해 조금 더 자세히 연구하여 2.주제 연구 파트에 작성합니다. 질병이라면, 그 질병의 증상, 원인, 치료법 등을 조사합니다. 이 과정에서 연구하는 생명현상과 관련된 유전자도 같이 조사합니다. 전문 연구 자료나 신문 기사 등의 자료를 수집합니다. 또는 병원이나 정부 기관 등의 믿을 수 있는 기관의 온라인 정보를 조사할 수도 있습니다. 조사한 정보를 사용할 때는 출처를 표기합니다.
3. 유전자 선정에는 생명현상과 관련된 유전자에 대해 설명하고, 해당 유전자의 기능과 서열에 대한 정보를 조사합니다. 유전자의 이름을 NCBI에서 검색하고, 해당 유전자의 일반적인 기능을 조사합니다.
4. 유전자 서열 검색에는 선정한 유전자의 단백질 서열을 찾아 표기합니다. 검색에 사용한 검색어와 검색 방법 등을 기술하고, 찾은 서열은 index와 서열 정보를 기록합니다.
5. 진화적 연관 유전자 검색은 NCBI 서열 데이터에서 진화적으로 관련된 서열 정보를 찾는 과정입니다. Activity 3의 내용을 참고하여, 진화적으로 관련 있는 서열을 NCBI에서 받습니다. 해당 파일들은 중간고사 과제 폴더에 저장(drag and drop)합니다.
6. Multiple sequence alignment를 통해 해당 유전자 서열을 정렬합니다. clustal omega를 이용하여 MSA를 만들 수 있습니다. MSA를 어떻게 수행했는지 기록하고, 그 결과 파일을 기록합니다.
7. Phylogenetic tree 파트에서는 alignment 결과를 이용해 phylogenetic tree를 그리고, 찾은 유전자와 가장 가까운 유전자는 무엇인지 기술하는 등, 유전자의 관계에 대해 기술합니다.
마지막으로 유전자의 기능을 이해하기 위해서 8. Domain analysis 파트에서 InterPro를 통해 유전자에 어떤 family 혹은 domain이 있는지 조사하고, 그 결과를 표기합니다. 해당 유전자의 일반적인 기능이 무엇인지 설명하고, 그 유전자는 어떤 domain으로 구성되어 있는지, 각 domain의 기능은 무엇인지 조사하고 설명합니다.
1. 주제 선정
중간 과제를 위해 연구할 주제를 선택하기 위해 평소에 관심을 가지고 있었던 생물학적 현상에 대해 조사합니다. 질병이나, 인체 현상, 동식물 혹은 미생물을 포함한 다양한 생명현상이 모두 대상이 될 수 있습니다.
조사한 현상에 대해 간략하게 설명하고, 어떤 자료를 조사했는지 설명합니다. 예를 들어 새치에 관심 있다면, 관련 정보를 인터넷에서 수집할 수 있습니다. 최근 BRIC 기사를 통해 Slc45a 유전자가 색소 형성에 관여하며 새치와 관련 있다는 연구 내용을 찾을 수 있었습니다.
### 성장기 새치 형성의 원인 분석<br>
* Slc45a 유전자에 의한 색소 형성 조절
* (참고 자료) https://www.ibric.org/bric/trend/bio-news.do?
mode=view&articleNo=9897980&article.offset=30&articleLimit=15#!/list두 개 이상의 생명 현상에 대한 자료를 수집하고, 그 내용을 기록합니다. 이 때 참고한 자료의 출처도 함께 기록합니다.
- 기사 참고: https://www.ibric.org/trend/news/index.php
- (tip) 사람과 관련 있는 생명현상을 선정합니다.
- (tip) 질병을 선정하면 관련 유전자 등 정보 수집이 용이합니다.
- (tip) 자세히 연구하기 전, 해당 주제와 관련된 단백질 coding 유전자가 있는지 먼저 간단히 분석합니다. 관련 유전자를 찾기 힘들다면 주제를 변경합니다.
2. 주제 연구
선정한 주제와 관련된 자료를 수집합니다. 질병이라면, 그 질병의 증상, 원인, 치료법 등을 조사합니다. 이 과정에서 연구하는 생명현상과 관련된 유전자도 같이 조사합니다. 전문 연구 자료나 신문 기사 등의 자료를 수집합니다. 또는 병원이나 정부 기관 등의 믿을 수 있는 기관의 온라인 정보를 조사할 수도 있습니다. 조사한 정보를 사용할 때는 출처를 표기합니다.
3. 유전자 선정
주제와 관련 있는 유전자를 찾습니다. 예를 들어 질병에 대해 연구하신다면, 질병의 원인이 되는 유전자에 대한 자료를 수집합니다. 여러 유전자 중 앞으로 연구할 유전자 하나를 선택합니다. 데이터베이스 검색을 위해 해당 유전자의 영문명을 찾습니다.
4. 유전자 서열 검색
먼저 해당 유전자의 서열을 찾기 위해 NCBI에서 유전자를 검색합니다. 아래 링크에서 유전자 이름을 키워드로 검색하면 단백질에 대한 정보를 찾을 수 있습니다. 이 때 유전자 영문명과 ‘Homo Sapiens’를 동시에 검색어로 이용하여 사람의 유전자를 찾습니다.
검색되어 나온 유전자/단백질 이름과 기타 정보 (GenBank ID 등)를 기록 합니다.
검색 결과 중 사람에 해당하는 항목을 클릭하면, 보다 자세한 데이터를 가진 페이지로 이동할 수 있습니다. 해당 페이지 상단에 ‘FASTA’라는 링크를 클릭하면 단백질 서열을 표시하는 페이지로 이동할 수 있습니다. “>”부터 시작하는 단백질 서열 정보를 Research Note에 기록합니다.
(*) 과제 진행 각 과정의 목적 등에 대한 설명을 Research Note에 추가하면서, 어떤 일을 수행하고 있는지 생각해 보고 그 내용을 기록합니다.
5. 진화적 연관 유전자 검색
유전자 서열을 이용해서 진화적으로 연관된 유전자를 찾습니다. NCBI BLAST에 단백질 서열을 입력으로 넣어 검색합니다. Database는 “Reference proteins (refseq protein)”을 선택합니다.
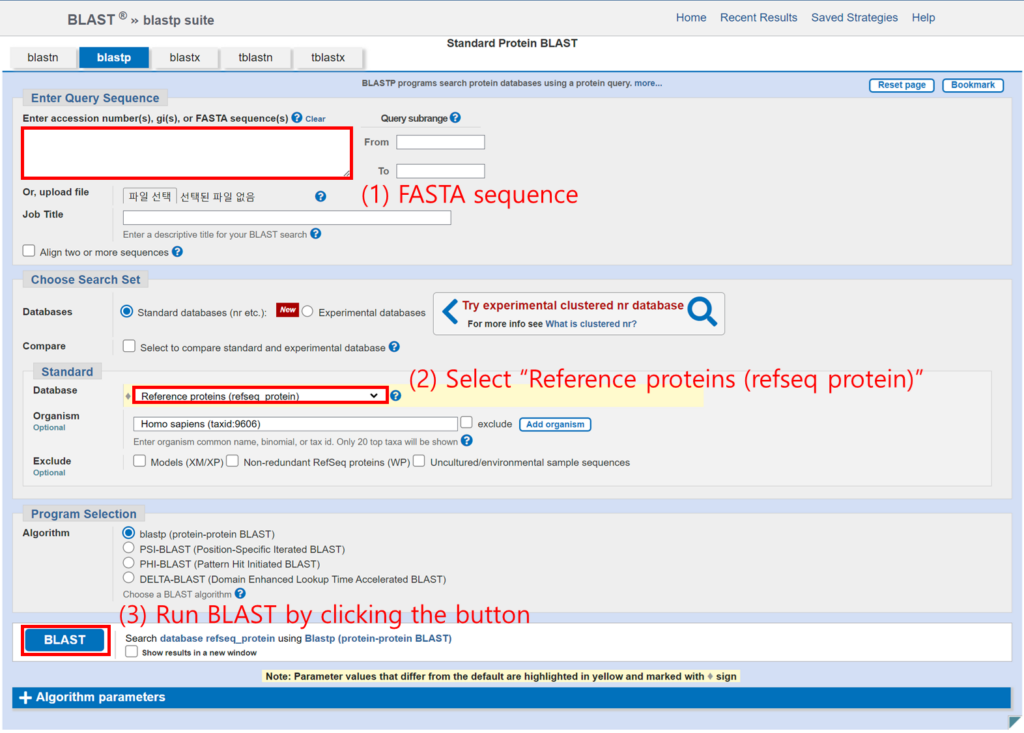
6. Multiple sequence alignment
BLAST 결과 얻은 서열을 다운 받습니다. (Download > FASTA (aligned sequences)). 다운 받은 파일 (seqdump.txt)를 JupyterNotebook으로 복사합니다.
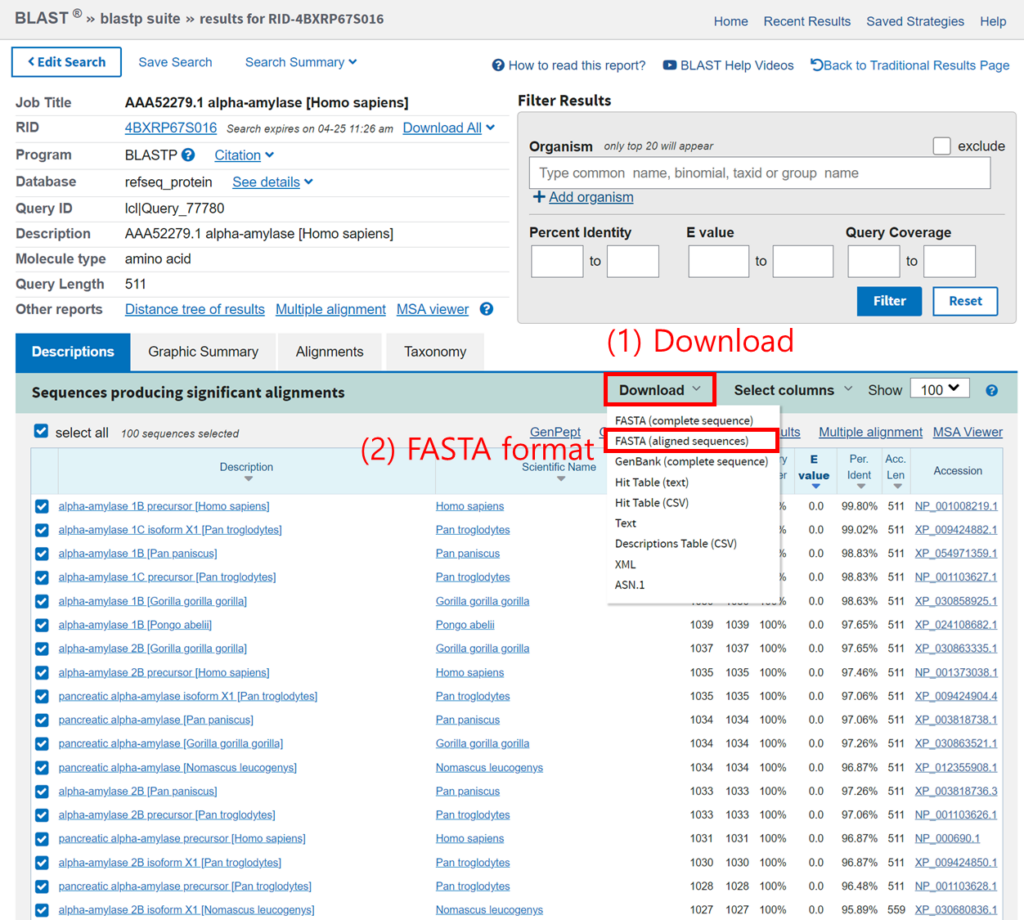
Terminal에서 clustalo 프로그램을 이용해 MSA를 진행합니다.
$ cd ~
$ cd MidTermProject
$ clustalo -i seqdump.txt -o aligned.txt7. Phylogenetic tree
MSA 서열을 이용하여 phylogenetic tree를 그리고, 어떤 유사한 서열을 지닌 단백질이 무엇인지 설명한다. https://bdsl.jbnu.ac.kr/blog/activity_for_phylogenetic_tree/ 참고
8. Domain analysis
InterPro를 이용하여 단백질안에 어떤 도메인이 있는지 찾고, 각 도메인의 기능을 설명하고, 유전자의 기능을 설명한다. Activity 5 참고.
II. 보고서 작성
연구 진행 결과를 정리하여 보고서를 작성합니다.
- 소개
- 연구 주제에 대해 설명합니다. 연구하고 싶은 유전자가 무엇인지, 그 유전자가 연구 주제와 어떻게 관련되어 있는지 설명합니다.
- 방법
- 연구 방법에 대해 설명합니다. BLAST를 이용해 연관 유전자를 검색한 내용과, 연관 유전자의 관계를 찾기 위해 MSA를 수행하고 phylogenetic tree를 그린 방법을 설명합니다. 마지막으로 domain을 찾는 방법을 설명합니다. 여기서는 방법만 설명하고, 결과는 다음에 소개합니다.
- 결과
- 분석한 결과를 설명합니다. BLAST를 통해 찾을 수 있는 유전자들의 기능을 설명하고, 진화적으로 연관된 단백질에 어떤 것들이 있는지 설명합니다. 이 대 phylogenetic tree 결과도 같이 소개할 수 있습니다.
- 유전자가 지닌 domain의 기능들을 설명합니다.
- 결론
- 결과를 통해 알 수 있었던 점이 무엇인지 요약하고, 특히 연구 주제에 비춰 어떤 의미가 있는지 설명합니다.