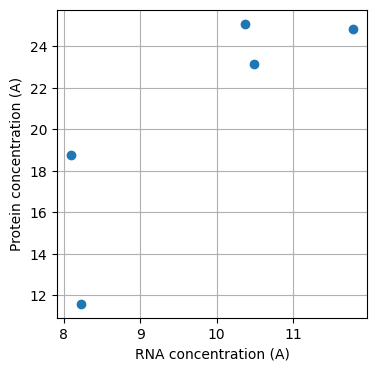
We have a statistic called Pearson’s correlation coefficient, which has a value of 0.86.
Since the value is larger than 0, we can say that the experimental results support the hypothesis that the RNA and protein expression levels of Protein A are positively correlated.
Random Incidences
However, we need to consider whether our interpretation is valid.
To test this, we will generate the same statistic using two independent variables, repeating this process five times.
We found 3 out of 5 random association had a Pearson correlation coefficient (PCC) greater than 0.
Therefore, observing a PCC greater than 0 might be too loose a criteria.
for i in range(5):
rvs = generate_random_values_B()
print(calculate_correlation(rvs)[0])
Let’s generate more random numbers and calculate PCC multiple times.
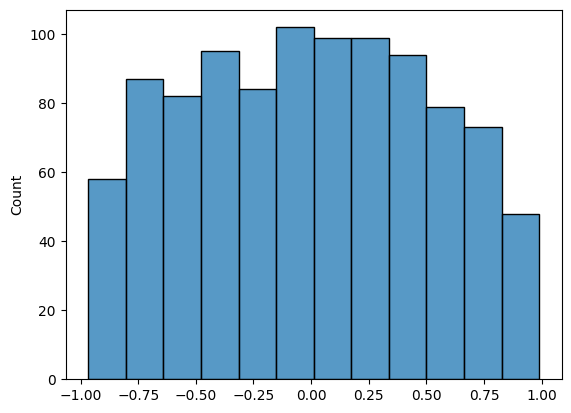
We repated this process 1000 times, obtaining a distribution of PCC values.
Among these, 30 instances had a PCC greater than 0.85, representing 3% of the cases (30/1000 = 3%).
In other words, we can observer a PCC larger than 0.85 in 3% of the experiments, even when the two variables are not correlated.
rhos= []
cnt = 0
for i in range(1000):
rvs = generate_random_values_B()
rhos.append(calculate_correlation(rvs)[0])
if calculate_correlation(rvs)[0] > 0.85:
cnt += 1
sns.histplot(rhos)
print(cnt)
P-value
We can calculate the probability of observing a statistic when the two variables are not correlated.
The probability is called the p-value.
We can estimate the p-value through simulation, as demonstrated above.
However, in certain cases, we can calculate the p-value exactly.
In other words, p-values can often be calculated quickly without the need for simulation.
Pearson’s correlation coefficient is one such statistic with a well defined distribution, allowing us to calculate the p-value accurately.
You can calculate PCC using stats.pearsonr function of scipy package.
Statistical inference
Now, we can make a statistical inference using the p-value.
Typically, we set a cutoff for the p-value, with 0.05 or 5% being the most commonly used threshold.
If the p-value of a statisic for an observation is less than 5%, we call the observation statistically significant, as it is unlikely (less than 5% probability) to have occurred by chance.